Datasets¶
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import logging
import os
import warnings
import torch
os.chdir("../..")
warnings.filterwarnings("ignore")
warnings.simplefilter("ignore")
logging.disable(logging.ERROR)
N_THREADS = 8
IS_FORCE_CPU = False # Nota Bene : notebooks don't deallocate GPU memory
if IS_FORCE_CPU:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
torch.set_num_threads(N_THREADS)
1D Gaussian Process Datasets¶
A good way to compare members of the NPFs is by trying to model samples from different Gaussian processes. Specifically, we will investigate NPFs in the following three settings:
Samples from a single GP the first question we want to understand is how well NPFs can model a ground truth GP. To test this hypothesis, we will repeatedly sample from a single GP and then compare the posterior predictive to the ground truth GP. Note that this is not really a natural setting, but the goal is to understand how biased the objective is and which NPF can best approximate the ground truth GP with finite computation. We will
Training : 100 epochs, each epoch consists of 10k different context and target sets from the GP (never see the same example twice)
Datasets : 3 datasets, each corresponding to a GP with a different kernel with fixed hyper-parameters. Namely : RBF, Exp-Sine-Squared (periodic), Matern with noise.
Evaluation : compare to the ground truth GP
Samples from GPs with varying Kernels in the second experiment will investigate whether members of the NPF can model a ground truth GP even it was trained on samples from different kernels. I.e. if it can “recognize” the kernel and model the ground truth GP once it does. To do so we will simply train on the 3 datasets from the first point.
Training : 100 epochs, each epoch consists of 10k different context and target sets from the GP (never see the same example twice)
Datasets : union of the 3 datasets from the first point
Evaluation : evaluate on each 3 datasets separately and compare to the ground truth GP
Samples from GPs with varying Kernel hyperparameters finally we will test whether the NPFs can model a family of GPs.
Training : 100 epochs, each epoch consists of 10k different context and target sets from the GP (never see the same example twice)
Datasets : Data generated by sampling a length scale \([0.01, 0.3]\) and then a function from a GP with Matern kernel and the corresponding length scale
Evaluation : compare to a GP with Matern Kernel, with a length scale fitted on the context points (using the marginal likelihood)
Extensions
See the docstrings of
GPDatasetfor more parameters.Adding a dataset from a new kernel is straightforward by defining your own kernel and following the same step as below.
# GPDataset Docstring
from utils.data import GPDataset
print(GPDataset.__doc__)
Dataset of functions generated by a gaussian process.
Parameters
----------
kernel : sklearn.gaussian_process.kernels or list
The kernel specifying the covariance function of the GP. If None is
passed, the kernel "1.0 * RBF(1.0)" is used as default.
min_max : tuple of floats, optional
Min and max point at which to evaluate the function (bounds).
n_samples : int, optional
Number of sampled functions contained in dataset.
n_points : int, optional
Number of points at which to evaluate f(x) for x in min_max.
is_vary_kernel_hyp : bool, optional
Whether to sample each example from a kernel with random hyperparameters,
that are sampled uniformly in the kernel hyperparameters `*_bounds`.
save_file : string or tuple of strings, optional
Where to save and load the dataset. If tuple `(file, group)`, save in
the hdf5 under the given group. If `None` regenerate samples indefinitely.
Note that if the saved dataset has been completely used,
it will generate a new sub-dataset for every epoch and save it for future
use.
n_same_samples : int, optional
Number of samples with same kernel hyperparameters and X. This makes the
sampling quicker.
is_reuse_across_epochs : bool, optional
Whether to reuse the same samples across epochs. This makes the
sampling quicker and storing less memory heavy if `save_file` is given.
kwargs:
Additional arguments to `GaussianProcessRegressor`.
Samples from a single GP¶
from sklearn.gaussian_process.kernels import RBF, ExpSineSquared, Matern, WhiteKernel
from utils.ntbks_helpers import get_gp_datasets
def get_datasets_single_gp():
"""Return train / tets / valid sets for 'Samples from a single GP'."""
kernels = dict()
kernels["RBF_Kernel"] = RBF(length_scale=(0.2))
kernels["Periodic_Kernel"] = ExpSineSquared(length_scale=1, periodicity=0.5)
#kernels["Matern_Kernel"] = Matern(length_scale=0.2, nu=1.5)
kernels["Noisy_Matern_Kernel"] = WhiteKernel(noise_level=0.1) + Matern(
length_scale=0.2, nu=1.5
)
return get_gp_datasets(
kernels,
is_vary_kernel_hyp=False, # use a single hyperparameter per kernel
n_samples=50000, # number of different context-target sets
n_points=128, # size of target U context set for each sample
is_reuse_across_epochs=False, # never see the same example twice
)
# create the dataset and store it (if not already done)
(datasets, _, __,) = get_datasets_single_gp()
import matplotlib.pyplot as plt
from utils.visualize import plot_dataset_samples_1d
n_datasets = len(datasets)
fig, axes = plt.subplots(n_datasets, 1, figsize=(11, 5 * n_datasets), squeeze=False)
for i, (k, dataset) in enumerate(datasets.items()):
plot_dataset_samples_1d(dataset, title=k.replace("_", " "), ax=axes.flatten()[i], n_samples=3)
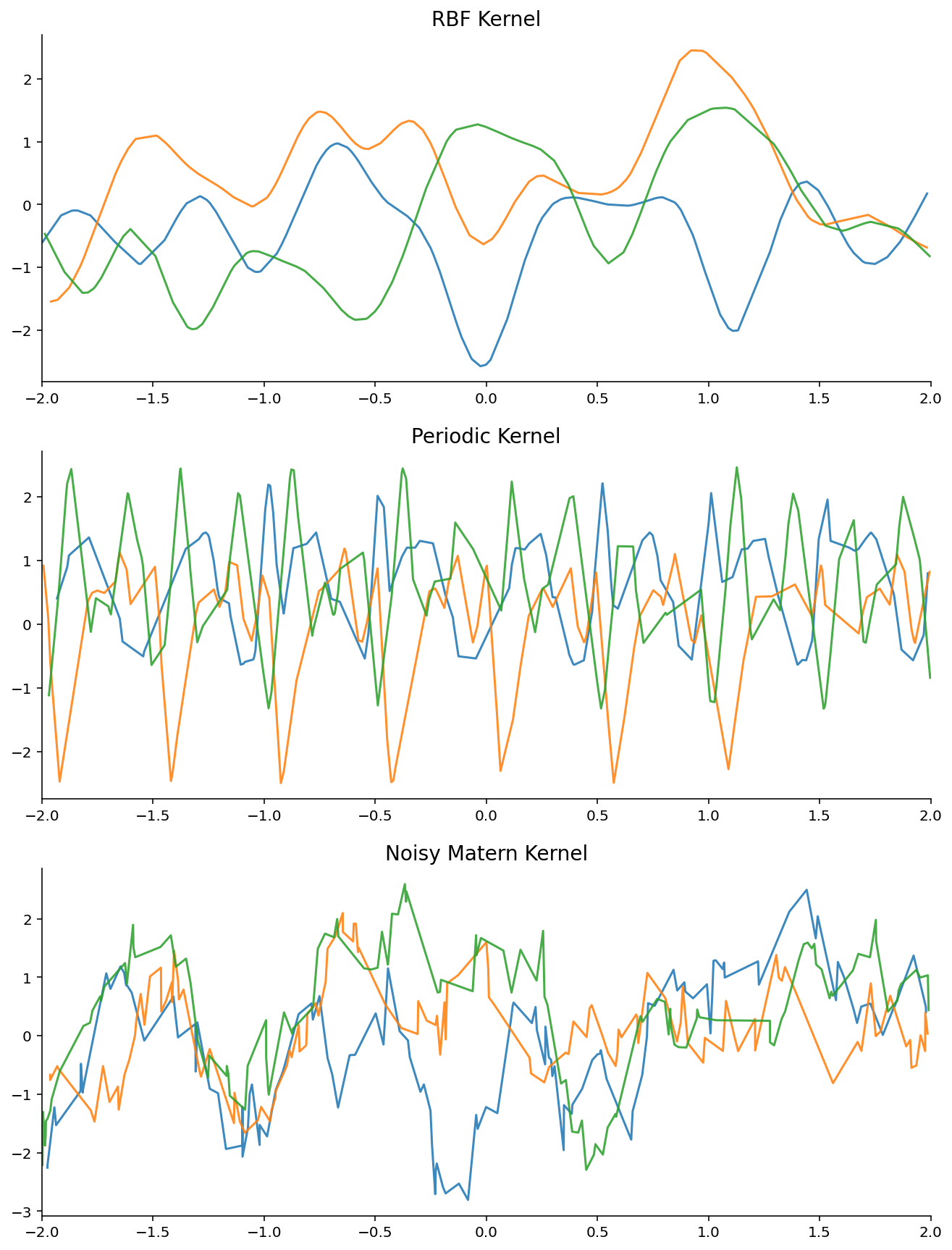
Samples from GPs with varying Kernels¶
from utils.data.helpers import DatasetMerger
def get_datasets_varying_kernel_gp():
"""Return train / tets / valid sets for 'Samples from GPs with varying Kernels'."""
datasets, test_datasets, valid_datasets = get_datasets_single_gp()
return (
dict(All_Kernels=DatasetMerger(datasets.values())),
dict(All_Kernels=DatasetMerger(test_datasets.values())),
dict(All_Kernels=DatasetMerger(valid_datasets.values())),
)
# create the dataset and store it (if not already done)
(datasets, _, __,) = get_datasets_varying_kernel_gp()
n_datasets = len(datasets)
fig, axes = plt.subplots(n_datasets, 1, figsize=(11, 5 * n_datasets), squeeze=False)
for i, (k, dataset) in enumerate(datasets.items()):
plot_dataset_samples_1d(dataset, title=k.replace("_", " "), ax=axes.flatten()[i], n_samples=10)
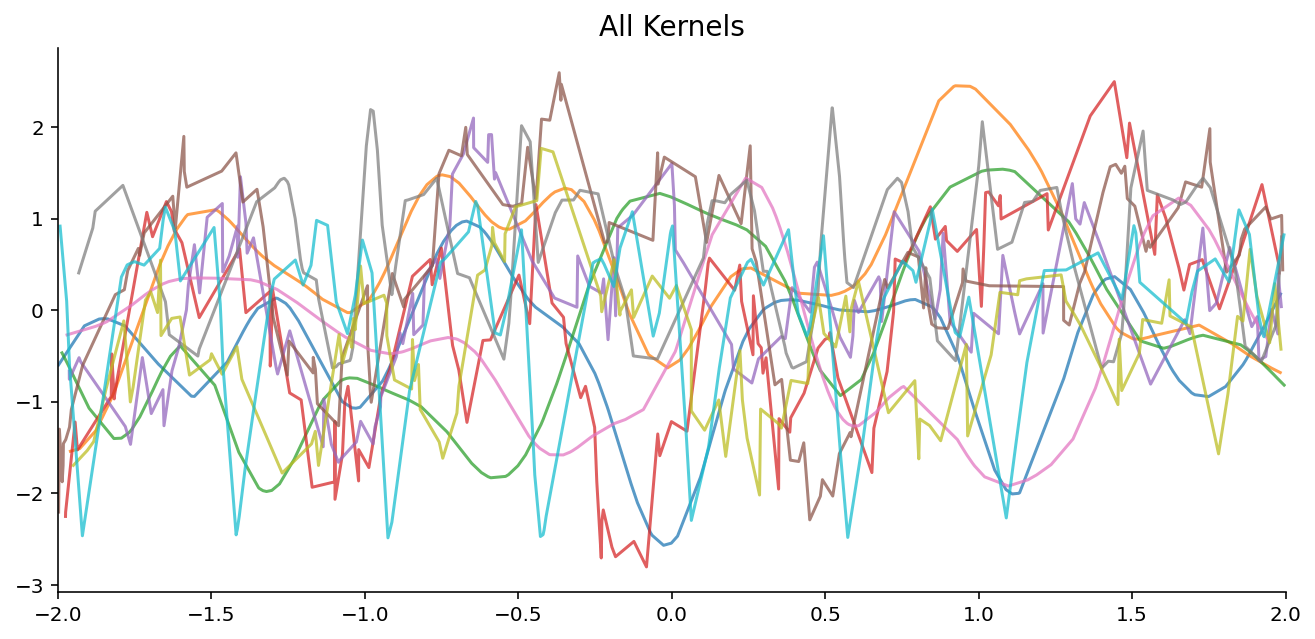
Samples from GPs with varying Kernel hyperparameters¶
def get_datasets_variable_hyp_gp():
"""Return train / tets / valid sets for 'Samples from GPs with varying Kernel hyperparameters'."""
kernels = dict()
kernels["Variable_Matern_Kernel"] = Matern(length_scale_bounds=(0.01, 0.3), nu=1.5)
return get_gp_datasets(
kernels,
is_vary_kernel_hyp=True, # use a single hyperparameter per kernel
n_samples=50000, # number of different context-target sets
n_points=128, # size of target U context set for each sample
is_reuse_across_epochs=False, # never see the same example twice
)
# create the dataset and store it (if not already done)
(datasets, _, __,) = get_datasets_variable_hyp_gp()
n_datasets = len(datasets)
fig, axes = plt.subplots(n_datasets, 1, figsize=(11, 5 * n_datasets), squeeze=False)
for i, (k, dataset) in enumerate(datasets.items()):
plot_dataset_samples_1d(dataset, title=k.replace("_", " "), ax=axes.flatten()[i], n_samples=5)
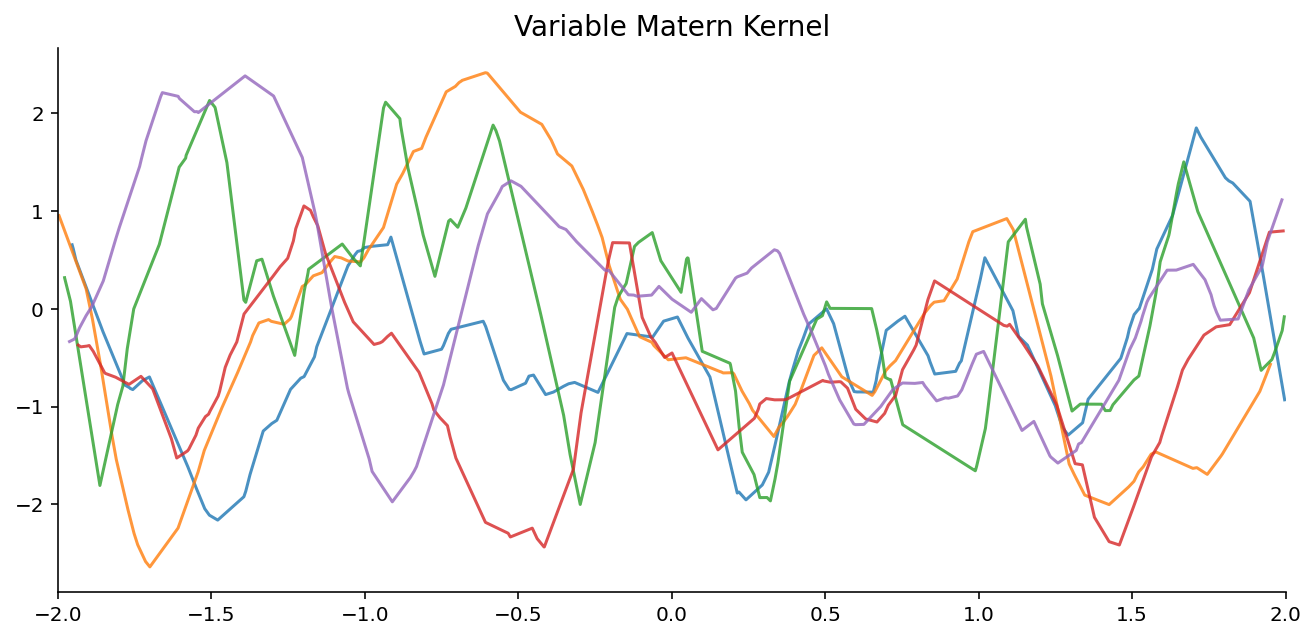
Image Datasets¶
We will be using the following datasets
MNIST [LBB+98]
CelebA [LLWT18] (rescaled to \(32 \times 32\) pixels)
Zero Shot Multi MNIST [GBF+20] (ZSMM).
Note
We will follow [FBG+20] for ZSMM. Namely, train on translated MNIST and test on a larger canvas with multiple digits (ZSMM).
from utils.data import get_train_test_img_dataset
datasets = dict()
_, datasets["CelebA32"] = get_train_test_img_dataset("celeba32")
_, datasets["MNIST"] = get_train_test_img_dataset("mnist")
from utils.visualize import plot_dataset_samples_imgs
n_datasets = len(datasets)
fig, axes = plt.subplots(1, n_datasets, figsize=(5 * n_datasets, 5))
for i, (k, dataset) in enumerate(datasets.items()):
plot_dataset_samples_imgs(dataset, title=k, ax=axes[i])

Let us now visualize some training and testing samples from ZSMM:
datasets_zsmm = dict()
datasets_zsmm["ZSMM Train"], datasets_zsmm["ZSMM Test"] = get_train_test_img_dataset("zsmms")
from utils.visualize import plot_dataset_samples_imgs
n_datasets = len(datasets_zsmm)
fig, axes = plt.subplots(1, n_datasets, figsize=(5 * n_datasets, 5))
for i, (k, dataset) in enumerate(datasets_zsmm.items()):
plot_dataset_samples_imgs(dataset, title=k, ax=axes[i])
